June 11, 2026
Claude Fable 5: A Practical Guide for Production AI Workflows
Learn what Claude Fable 5 is, how to use it for long-running AI workflows, and which guardrails, review gates, and evaluation checks to add before launch.
Article focus
Claude Fable 5 is a practical fit for teams that want AI agents to handle longer coding, reporting, and operations workflows, but only when the work is scoped, observable, and reviewable.
Section guide
Claude Fable 5 is a practical fit for teams that want AI agents to handle longer coding, reporting, and operations workflows, but only when the work is scoped, observable, and reviewable. This Claude Fable 5 guide gives founders, data leaders, and AI product teams a production plan: choose the right workflow, define the handoffs, add guardrails, and measure whether the agent beats the current process.
The buyer problem is not "can the model do impressive work?" It is whether your team can trust a longer-running agent to touch code, data, dashboards, customer-facing documents, or internal operations without creating hidden review debt.
At Van Data Team, we start by mapping the business workflow before selecting the model. For this kind of implementation, that usually means a combination of AI agent development, data access design, workflow automation, reporting, review gates, and delivery standards. The model is one part of the system. The operating layer around it is what determines whether the work becomes useful.
Key Takeaways
- Use Fable for bounded long-horizon work, not vague "autonomous agent" experiments with unclear acceptance criteria.
- The safest workflow pattern is plan, execute in stages, self-check, human review, then release or revise.
- Cost, latency, token budget, observability, review burden, and failure recovery should be measured during the pilot.
- Built-in safeguards are helpful, but they do not replace your own permissions, logging, approval gates, and escalation rules.
- A strong implementation starts with one workflow where output quality can be compared against the current manual process.
What Is Claude Fable 5?
Claude Fable 5 is Anthropic's next-generation Claude model for hard knowledge work, coding, and long-running agentic tasks. Anthropic positions it for ambitious work such as multi-stage coding projects, enterprise workflows, document-heavy analysis, and agents that can plan, delegate, and check their own work.
The official Anthropic Fable page describes it as built for difficult knowledge and coding problems, including asynchronous tasks previous models could not sustain. The Amazon Bedrock model card frames it around sustained autonomous operation, staged planning, sub-agent delegation, and self-verification.
The key implementation detail is that Fable is not simply a chat model upgrade. It is positioned around a more agentic operating style. That changes the project design. Instead of asking, "What prompt should we write?" the better question is, "What workflow can safely be delegated, monitored, evaluated, and improved?"
It also sits near Mythos 5 in the model family. Reporting from TechCrunch describes Fable as a public, safeguarded version of Mythos-class capability, with limits around high-risk areas such as cybersecurity, biology, and chemistry. For operators, those limits are not a footnote. They are part of the production design.
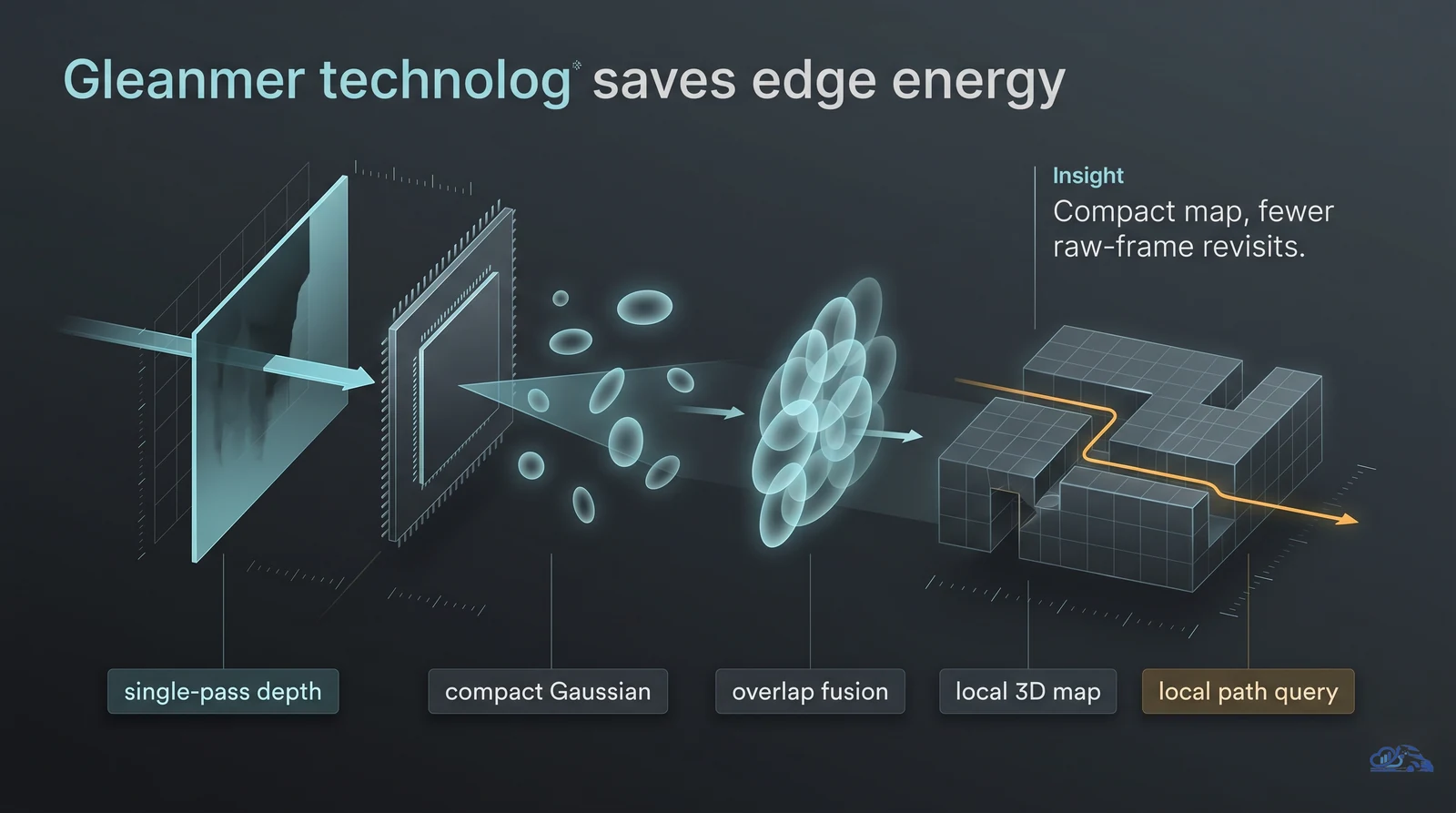
Where It Fits in Production Architecture
The following illustration summarizes production workflow around the model:

A production agent workflow has more parts than the model call. A workable architecture usually includes five layers:
- Input layer: user request, task brief, source documents, warehouse tables, code repository, dashboard, or ticket.
- Planning layer: the model turns the request into steps, risks, required tools, assumptions, and review points.
- Execution layer: the agent uses tools, reads data, writes code, drafts analysis, or creates workflow artifacts.
- Validation layer: tests, schema checks, retrieval checks, dashboard checks, human review, and policy filters.
- Delivery layer: pull request, report, dashboard note, ticket update, internal memo, or operational handoff.
The mistake we see is teams treating autonomy as a replacement for workflow design. That leads to demos that look impressive and operations that are hard to trust. A model can work through more steps, but your organization still needs to decide what it may access, what it may change, when it must stop, and who approves the result.
This is why platform context matters. Microsoft's announcement for Fable in Microsoft Foundry emphasizes governance, security, observability, and enterprise workflow integration. Those are not enterprise decorations. They are the difference between a clever assistant and a managed production system.
For teams with data-heavy workflows, the agent layer often depends on data pipeline engineering. If the agent is reading stale tables, undocumented metrics, or inconsistent event streams, the model's reasoning quality will not save the workflow.
How to Use It for a First Pilot
The right first pilot is boring enough to control and valuable enough to measure. Avoid starting with customer-impacting automation, financial approvals, compliance decisions, production infrastructure changes, or sensitive security tasks. Start with a workflow where a skilled person can review the result quickly.
A good pilot follows this sequence:
- Choose a bounded workflow. Examples include drafting a migration plan, investigating a reporting anomaly, producing a dashboard QA checklist, or preparing a pull request from a clear issue.
- Define the output before the run. The output should be concrete: a plan, test list, patch, annotated dashboard, metric explanation, or decision memo.
- Write acceptance criteria. Decide what counts as correct, incomplete, risky, or rejected before the agent starts.
- Add checkpoints. Require approval after the plan, after tool selection, before final changes, and before release.
- Log the run. Capture prompts, source files, tool calls, decisions, validation failures, refusals, fallbacks, and human overrides.
- Compare against baseline. Measure quality, review effort, elapsed time, failure rate, and whether the workflow reduced work or just moved it.
A practical Fable workflow should make review easier, not harder. If the human reviewer has to re-run every step from scratch, the implementation is not ready.
If your team is evaluating this for production, Van Data Team can turn the pilot into a scoped workflow review: the workflow map, risk points, data dependencies, guardrail design, review gates, dashboard gaps, and implementation backlog. Our Strategy Sprint is designed for that kind of bounded planning output.
Implementation Artifact: Task Brief Template
For long-running work, a structured task brief is better than a loose prompt. The goal is to give the agent enough operating context while keeping the work auditable.
1. Define the Claude Fable 5 decision.
2. List required inputs, owner, and stop conditions.
3. Run the smallest safe workflow.
4. Validate output quality before publishing or deployment.
5. Escalate unresolved risk to a human reviewer.
This format works because it separates objective, permissions, evidence, review, and failure behavior. It also gives your team a reusable artifact. Over time, each successful workflow becomes a template your agents can run with less ambiguity.
Practical Examples by Team
A software team might use Fable to handle a multi-stage codebase migration. The agent reads the issue, proposes an implementation plan, identifies affected modules, writes tests, creates a patch, and summarizes tradeoffs. The review gate comes before merge, not after deployment. The team should still require normal CI, code review, security review where relevant, and rollback notes.
A data team might use it to investigate a dashboard break. The agent checks metric definitions, recent pipeline changes, warehouse freshness, source-system delays, and dashboard filters. The output is not "the answer." The output is an evidence packet: likely causes, supporting queries, confidence level, and a validation checklist. This is where automated reporting workflows can become useful: dashboards can explain anomalies, but uncertain findings still route to a reviewer.
An operations team might use it to coordinate a recurring internal workflow. For example, an agent could collect updates from a project tracker, reconcile missing fields, draft an executive summary, and flag blocked items. The agent should not invent status. It should show missing inputs, link to the source records, and ask for review when the evidence is incomplete.
These examples share the same pattern. The model does more work, but the system stays explicit about permissions, evidence, and approval.
Best Practices for Safer Workflows
The best practices are operational, not cosmetic.
Use structured briefs. A vague prompt produces vague control. A structured brief defines the business goal, allowed tools, data sources, review points, and failure behavior.
Break long work into artifacts. Ask for a plan, then evidence, then draft output, then validation. Each stage should be reviewable on its own.
Keep humans in sensitive paths. Customer-facing, financial, compliance, security, legal, and operationally irreversible outputs need review. Self-verification is useful, but it is not independent assurance.
Design fallback behavior. The agent may refuse, hit safeguards, lose context, call the wrong tool, or produce uncertain findings. Define whether it should stop, escalate, use another model, ask a clarifying question, or produce a partial report.
Measure review burden. A workflow that saves two hours of drafting but creates three hours of checking is not an improvement. Review time belongs in the evaluation plan.
Verify current platform constraints. The AWS model card lists a 1M token context window and 128K maximum output tokens, along with a January 2026 knowledge cutoff. Those specs affect architecture, but they should still be checked against the current provider documentation before deployment.
| Dimension | What to Measure | Why It Matters |
|---|---|---|
| Cost | Token use, tool calls, retries, and review time | Agentic work can consume more budget than short chat tasks. |
| Latency | Time to plan, execute, validate, and revise | A slower workflow may be fine for research, but not for live operations. |
| Token budget | Context used by files, logs, schemas, and prior steps | Large context helps, but irrelevant context can increase cost and confusion. |
| Observability | Prompt logs, tool traces, decision logs, and reviewer notes | You need to debug failures after the run, not guess what happened. |
| Evaluation | Correctness, completeness, confidence, and business outcome | Completion alone does not prove the workflow worked. |
| Failure recovery | Stop rules, fallbacks, escalation, and rollback paths | Production systems need a known response when the agent gets stuck. |
Common Mistakes to Avoid
The first mistake is using autonomy as the strategy. More capable models make weak workflow design more visible. If the process is unclear for a human, it will usually be unclear for an agent.
The second mistake is skipping validation because the model can self-check. Self-verification is useful for catching obvious gaps, but it does not replace tests, source reconciliation, domain review, or business approval.
The third mistake is giving the agent too much authority too early. Read-only access is usually the right starting point. Write access, deployment access, and customer communication should come later, after the workflow has proven itself.
The fourth mistake is measuring only speed. A faster wrong answer is worse than a slower correct process. Track quality, rework, reviewer confidence, and downstream impact.
The fifth mistake is publishing volatile claims without checking the live source. Pricing, availability, fallback behavior, retention terms, and model limits can change. Treat those as deployment checks, not evergreen assumptions. Anthropic's current Fable page, for example, discusses safeguards, fallback behavior, pricing, and data retention in terms teams should review before production use.
The Five-Part Implementation Framework
Use this Claude Fable 5 framework when moving from evaluation to implementation.
| Step | Question | Output |
|---|---|---|
| Scope | What job should the agent do, and what risk level does it carry? | Workflow map and risk rating |
| Structure | What stages, tools, data sources, and artifacts are required? | Task brief and execution plan |
| Supervise | Where must a person review, approve, or stop the run? | Review gate design |
| Validate | What objective checks prove the output is good enough? | Test plan and evaluation rubric |
| Improve | What failures should be logged and fed back into the workflow? | Issue log and iteration backlog |
This structure keeps implementation grounded. It also helps teams compare Fable against simpler patterns: a standard LLM call, a rules-based automation, a human SOP, or a less expensive model. If the work is short, repetitive, and deterministic, a simpler automation may be better. If the work requires planning across stages, interpreting messy context, using tools, and producing reviewable deliverables, a Fable-style agent workflow becomes more compelling.
Conclusion
Claude Fable 5 matters because it pushes teams toward more autonomous AI workflows: longer tasks, richer context, staged execution, and self-checking behavior. But the winning pattern is not to turn the model loose. It is to build structured autonomy around a real business process.
Start with one bounded workflow. Define the inputs, permissions, review gates, validation checks, and fallback behavior. Run the pilot against a current manual baseline. Then decide whether the model, workflow design, and review burden justify production use.
For teams exploring Claude Fable 5 implementation, Van Data Team can help produce the practical assets that make the decision concrete: a workflow map, signal map, dashboard gap review, guardrail plan, evaluation rubric, and delivery scope. That is the work that turns a promising model into an operating system for real business execution.
Article FAQ
Questions readers usually ask next.
These short answers clarify the practical follow-up questions that often come after the main article.
Need a similar system?
If this article maps to a workflow your team already operates, the next step is usually a scoped review of the system, constraints, and rollout path.
Free agent review
Make Claude Fable 5 Production-Ready
Map your Claude Fable 5 workflow, review guardrails and handoffs, and leave with launch-ready next steps for a bounded pilot.
- A scoped Claude Fable 5 pilot workflow
- Recommended human review checkpoints
- Tool permissions and escalation rules
- Observability and evaluation metrics
- Concrete next steps for implementation
Related articles
View all
AI Governance Lessons from NVIDIA's Board Appointment

Djinn Stealer and ChocoPoC: the new attacks on AI coding assistants and the Zero Trust DevSecOps response

Grok 4.5 and the SpaceX Cursor Acquisition: What It Means for AI-assisted Software Engineering