June 21, 2026
Unverified GPT-5.6 soft launch reports and what they mean for AI-assisted software engineering: what is confirmed?
Unverified GPT-5.6 reports need evidence, not hype. See how AI-assisted software teams should verify signals and prepare workflows before coding plans change.
Article focus
Unverified GPT-5.6 soft launch reports and what they mean for AI-assisted software engineering examples Unverified GPT-5.6 soft launch reports and what they mean for AI-assisted software engineering framework Unverified GPT-5.6 soft launch reports and what they mean for.
Section guide
As of June 21, 2026, there is no credible public evidence in the supplied research that OpenAI has leaked or softly launched GPT-5.6 in June 2026. For readers searching Unverified GPT-5.6 soft launch reports and what they mean for AI-assisted software engineering, the practical answer is: treat the reports as unverified planning signals, not product facts.
That still matters for CTOs, platform leads, AI engineering managers, and data teams because model-release rumors can distort roadmap timing, procurement decisions, evaluation plans, and developer tooling choices. The risk is not that a rumor exists. The risk is letting unsupported claims change how production software work gets designed.
At Van Data Team, we start by separating evidence from workflow impact. If a model rumor could affect coding assistants, data pipeline maintenance, AI agents, or platform automation, we turn it into an evidence map, a model-agnostic architecture review, and a set of release gates. That is how our AI and data engineering services make fast-moving AI decisions operational without letting rumor velocity become architecture policy.
Key Takeaways
- There is no credible public evidence in the supplied research that OpenAI has leaked or softly launched GPT-5.6 as of June 21, 2026.
- Secondary reports about backend references, screenshots, benchmarks, or agentic coding improvements should be treated as unverified until official documentation, release notes, or API availability appear.
- Engineering teams should prepare by making model integrations swappable, not by rebuilding roadmaps around a rumored model.
- The best response is an evaluation workflow: claim classification, repository-based tests, cost and latency measurement, human review gates, and rollback paths.
- AI-assisted software engineering will keep changing quickly, so teams need durable release-readiness practices more than they need speculation about a specific model name.
What the reports actually support
The supplied SERP includes secondary pages that discuss alleged GPT-5.6 leak signals, possible June timing, rumored coding improvements, claimed benchmark movement, possible interface changes, and backend-reference speculation. Those pages may be useful for understanding what the market is talking about. They are not enough to establish that OpenAI leaked, confirmed, announced, or softly launched GPT-5.6.
The official surfaces matter more. A publication-ready analysis should watch the OpenAI News page, the OpenAI model release notes, and the OpenAI API models documentation. If those sources do not list GPT-5.6, then the responsible wording is still "reports", "rumor coverage", or "unverified claims".
This distinction sounds editorial, but it is operational. A CTO reading rumor coverage might ask whether to delay a coding-agent rollout. A platform lead might wonder whether to pause evaluation work until a newer model appears. A procurement owner might ask whether a vendor contract should include GPT-5.6 access. None of those decisions should move on secondary coverage alone.
The mistake we see is treating model names as strategy. Model names change. API behavior changes. Pricing, latency, context handling, safety constraints, and tool support change. Your workflow should be built so those details can be evaluated and swapped without rewriting the operating model.
If your team is already under pressure to decide, the useful output is not a prediction. It is a scoped signal map: what has been reported, what is confirmed, what would change engineering behavior, and which release gates must pass before adoption.
A framework for evaluating unconfirmed model signals
Unverified GPT-5.6 soft launch reports are secondary claims that OpenAI may be testing or preparing a new model, but the supplied research does not confirm an official leak or launch. Engineering teams should treat those reports as planning signals, not evidence, and prepare model-agnostic AI coding workflows.
Use an evidence ladder before you discuss roadmap impact:
| Claim type | Evidence level | Engineering response |
|---|---|---|
| Blog rumor or social post | Low | Monitor, do not change roadmap |
| Screenshot or backend-reference report | Low to medium | Validate source, reproducibility, and timestamp |
| Repeatable API behavior observed in your account | Medium | Log evidence, isolate test environment, avoid production dependency |
| Vendor documentation or platform changelog | High | Begin controlled evaluation |
| Official release notes and model docs | High | Test against internal benchmarks |
| Production API availability with terms and pricing | Highest | Consider staged rollout with governance |
The key is to define what each signal permits. A blog rumor permits monitoring. It does not permit architecture rewrite. A reproducible API observation permits sandbox testing. It does not permit committing customer-facing deadlines. Official model documentation permits evaluation. It still does not permit production rollout without tests.
A practical evidence review should answer five questions:
- What source made the claim?
- Is the source primary, secondary, or speculative?
- Does the claim affect a live workflow?
- What internal test would prove the model is useful for that workflow?
- What rollback path exists if the model is slower, more expensive, or less reliable than expected?
This is where governance should stay boring. The OWASP Top 10 for Large Language Model Applications calls out risks such as insecure output handling, excessive agency, and overreliance. Those concerns apply whether the model is GPT-5.6, GPT-5.5, Claude, Gemini, or an internal model. New capability does not remove the need for review gates.
Implementation architecture for AI-assisted engineering
The following illustration summarizes model signals enter through gates:
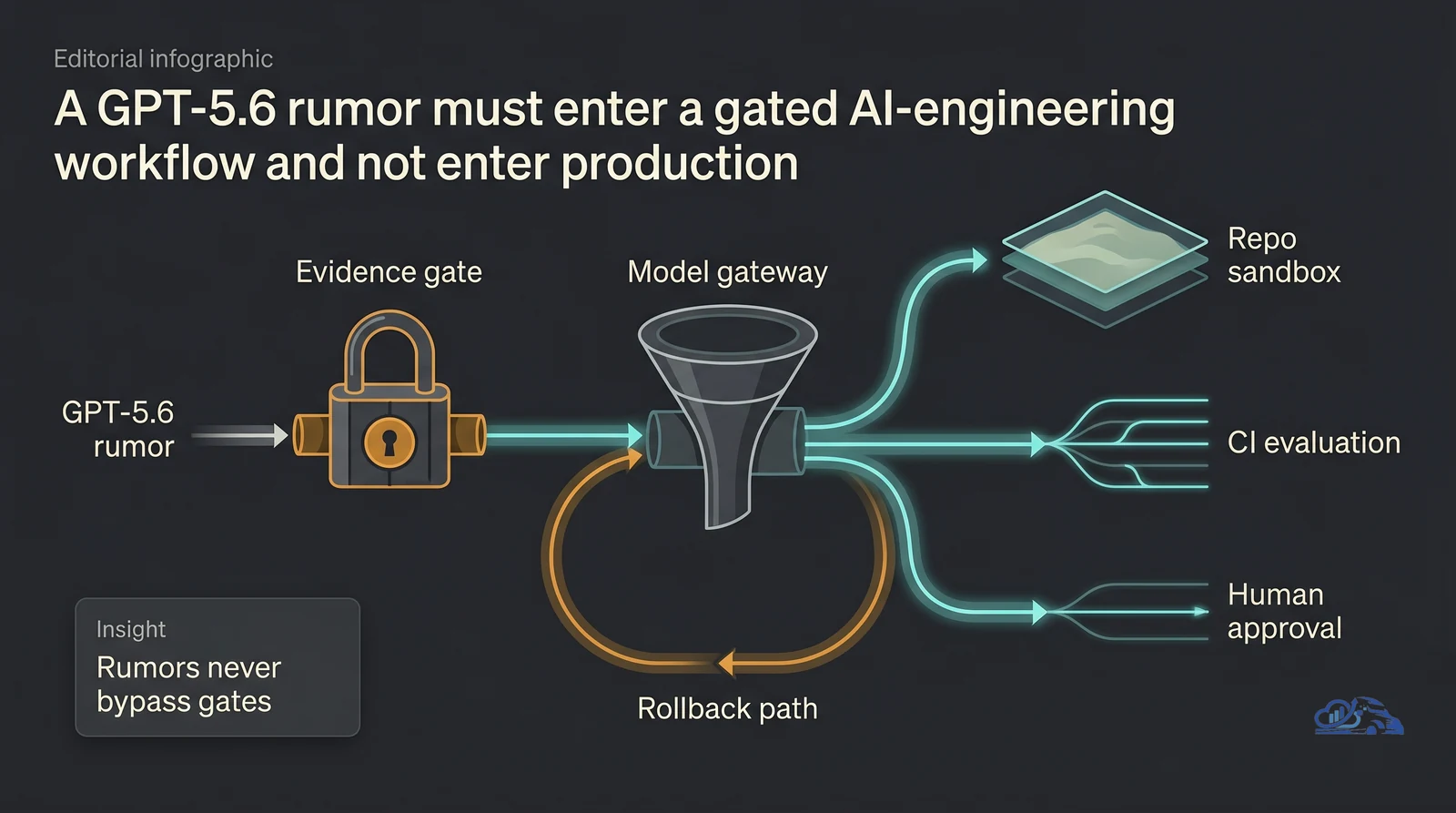
A useful Unverified GPT-5.6 soft launch reports and what they mean for AI-assisted software engineering framework should not depend on GPT-5.6 existing. It should describe how your engineering workflow absorbs any credible model upgrade.
The architecture should have seven layers:
- Request layer: developer prompt, ticket, bug report, pull request, or data pipeline issue
- Policy layer: approved task types, forbidden actions, data handling rules, and tool permissions
- Model gateway: swappable model provider interface with routing, rate limits, and cost controls
- Repository sandbox: isolated branch, test database, mock secrets, and controlled filesystem access
- Evaluation layer: unit tests, integration tests, security checks, static analysis, and task-specific graders
- Human review gate: code owner review, data owner review, or release manager approval
- Audit and rollback layer: trace logs, diff records, run IDs, deployment status, and rollback instructions
For teams modernizing brittle data foundations, this model gateway belongs alongside the broader data platform modernization plan. AI coding assistants become risky when they are bolted onto unclear ownership, weak tests, and undocumented pipelines. They become useful when the workflow already knows what "done", "safe", and "rollback" mean.
A short policy artifact can keep the decision concrete:
1. Define the Leaked GPT-5.6 soft launch and what it means for AI-assisted software engineering decision.
2. List required inputs, owner, and stop conditions.
3. Run the smallest safe workflow.
4. Validate output quality before publishing or deployment.
5. Escalate unresolved risk to a human reviewer.
This is not bureaucracy for its own sake. It prevents a rumor from becoming an untracked dependency.
For example, a platform team might want an AI agent to repair failing Airflow DAGs. The agent can inspect logs, propose a fix, run tests, and open a pull request. But if it can also edit production connection settings, retry failed jobs without limits, or merge its own code, the workflow has crossed from assistance into unmanaged agency. A stronger design uses data pipeline engineering discipline: sandbox first, tests next, review before merge, deployment after approval.
Practical examples and failure modes
The best examples are not about GPT-5.6 itself. They are about how a team behaves when an unconfirmed model report appears.
A SaaS platform lead sees secondary coverage claiming a new coding model may handle longer autonomous debugging sessions. Their team is about to buy an AI coding tool for a monorepo. The weak response is to delay the entire rollout. The stronger response is to define the evaluation tasks now: flaky test repair, dependency upgrade, SQL migration review, and frontend bug reproduction. If a credible model appears later, it enters the same test harness.
A data engineering manager hears that a rumored model may be better at tool use. Their team maintains ingestion jobs that touch customer data. They do not give an agent write access to production tables. Instead, they create a dry-run environment, allow read-only logs, run proposed changes against fixtures, and require a human reviewer before any pipeline code lands.
A CTO reviewing budget pressure hears that a newer model may improve coding productivity. The wrong move is to assume lower delivery cost without measuring token spend, tool-call loops, review burden, and latency. Inference cost is only one line item. Longer agent runs can increase CI usage, sandbox time, reviewer load, and cloud spend. We have written separately about how teams can reduce AWS costs without slowing delivery, and the same operating principle applies here: map spend to workflows, not product names.
Common failure modes look like this:
| Failure mode | What it looks like | Better response |
|---|---|---|
| Rumor-led roadmap | "Wait for GPT-5.6 before shipping" | Ship model-agnostic workflow gates now |
| Benchmark overreach | "A public score means it will fix our repo" | Test on your real codebase and review rules |
| Cost blindness | "Better model means fewer hours" | Measure tokens, retries, CI time, and review load |
| Weak observability | "The agent failed, but we do not know where" | Log prompts, tools, diffs, tests, and reviewer decisions |
| Unsafe autonomy | "The agent can debug and deploy" | Separate diagnosis, patching, approval, and release |
A mid-article offer should be specific enough to be useful: Van Data Team can help turn this into a two-part workflow review. The output is a model-release signal map, an AI coding workflow diagram, a repository evaluation plan, and a delivery scope for the highest-value automation path. That is a better artifact than a yes-or-no answer about an unconfirmed model.
Readiness checklist for a sudden model release
If a credible model does launch suddenly, you do not want the first meeting to be about what to test. You want a checklist already agreed by engineering, security, data, and product.
Use this before any new AI coding model touches production work:
- Confirm the source through official documentation, release notes, or direct vendor communication
- Record model ID, availability surface, pricing page, data handling terms, and deprecation policy
- Test against real internal tasks, not generic demos
- Measure cost, latency, task success, failed tool calls, and reviewer correction rate
- Separate read-only analysis from write actions
- Require pull requests for code changes
- Run standard CI, security checks, and data quality checks
- Log prompts, tool calls, generated diffs, tests run, and final reviewer decision
- Define rollback behavior before deployment
- Re-evaluate after provider updates, model routing changes, or pricing changes
For AI-assisted software engineering, the highest-return work is often not the model switch. It is the harness around the model. Strong tests, clean repository boundaries, reproducible environments, and clear owners make every future model easier to evaluate.
This is also where measurable systems beat hype-driven architecture. In our Fortune 500 BigQuery warehouse case study, the value came from automated KPI delivery and repeatable reporting behavior, not from betting on a tool name. AI-assisted engineering should be judged the same way: what changed in the workflow, what became observable, and what can be recovered when something fails?
Conclusion: prepare without betting on rumors
The search term Unverified GPT-5.6 soft launch reports and what they mean for AI-assisted software engineering points to a real buyer concern, but the premise remains unconfirmed. As of June 21, 2026, there is no credible public evidence in the supplied research that OpenAI has leaked or softly launched GPT-5.6 in June 2026.
The right operating answer is not to amplify weak claims or ignore the model market. It is to build engineering systems that can absorb credible model upgrades safely.
That means evidence classification, swappable model gateways, repository-specific evaluations, cost and latency tracking, human review gates, and rollback-ready delivery. If the next model is useful, this architecture lets you test it quickly. If the rumor fades, the same work still improves your AI-assisted software engineering practice.
For teams that want a concrete next step, Van Data Team can scope a release-readiness review with four outputs: a signal map, a workflow risk review, an evaluation plan, and an implementation scope across agents, data pipelines, and platform automation. Start with what we build, then decide where AI assistance is safe enough to move from demo to production.
Article FAQ
Questions readers usually ask next.
These short answers clarify the practical follow-up questions that often come after the main article.
No. As of June 21, 2026, the supplied research does not include credible public evidence that OpenAI has leaked, confirmed, announced, or softly launched GPT-5.6. The responsible position is to monitor official sources and label secondary coverage as unverified.
No. Teams should improve the workflow now: model abstraction, repository sandboxing, evaluation harnesses, human review gates, cost tracking, and rollback paths. Those investments remain useful whether the next credible model is GPT-5.6 or something else.
The strongest signals would be official release notes, API model documentation, a model page, a system card, or production API availability with clear model IDs and terms. Repeatable observations inside your own vendor account can justify sandbox testing, but they still need official confirmation before production planning.
Use tasks from your own repositories. Good tests include bug fixes with known outcomes, migration tasks, flaky test diagnosis, SQL review, data pipeline repair, and documentation updates. Track success rate, diff quality, security issues, runtime, token use, reviewer corrections, and rollback effort.
Use them as a trigger to review readiness, not as evidence for adoption. Build an evidence log, name the workflows that could benefit from a stronger model, and define the tests that any new model must pass.
Run a staged evaluation. Start with read-only tasks, then pull-request generation, then limited internal workflows. Do not grant deployment, production data mutation, or autonomous merge permissions until the model passes your quality, security, cost, and review gates.
Need a similar system?
If this article maps to a workflow your team already operates, the next step is usually a scoped review of the system, constraints, and rollout path.
Free evidence review
Validate GPT-5.6 Engineering Impact
Separate GPT-5.6 rumors from engineering decisions and leave with a model-agnostic readiness plan, review checkpoints, and agent workflow priorities.
- Evidence map for GPT-5.6 soft-launch claims
- Risk list for coding assistants and agent workflows
- Model-agnostic architecture checks before any upgrade
- Human review checkpoints for tool-use changes
- Next-step evaluation plan for your engineering team
Related articles
View all
Did the US government ban Claude Fable 5?

Google DeepMind Launches $10M Multi-Agent AI Safety Initiative: What Production Teams Should Learn

Building AI agents with Model Context Protocol (MCP): A Practical Guide for Production Teams
